Understanding Gradients in Machine Learning by Implementing Numerical Differentiation and Gradient Checking From Scratch¶
When we train machine learning models using frameworks like PyTorch, TensorFlow, or JAX, we rely heavily on automatic differentiation.
These frameworks magically compute gradients for us.
But something bothered me while learning machine learning:
I was using gradients every day but didn't truly understand what was happening under the hood.
So I decided to implement the core ideas myself.
The goal of this project was to deeply understand:
- Numerical differentiation
- Gradients of multivariable functions
- Gradient checking
- Linear regression gradients
- Neural network gradients
This project forced me to connect calculus, optimization, and machine learning in a practical way.
Why Gradients Matter in Machine Learning¶
Nearly every machine learning model is trained using Gradient Descent.
The goal of training is simple:
We want to minimize a loss function.
Where:
- \(L\) = loss
- \(\theta\) = model parameters
Training updates parameters using the gradient:
Where:
- \(\alpha\) = learning rate
- \(\nabla L(\theta)\) = gradient of the loss
Intuitively:
Think of the loss function as a landscape of hills and valleys.
The gradient tells us:
Which direction is downhill?
Visualizing Optimization¶
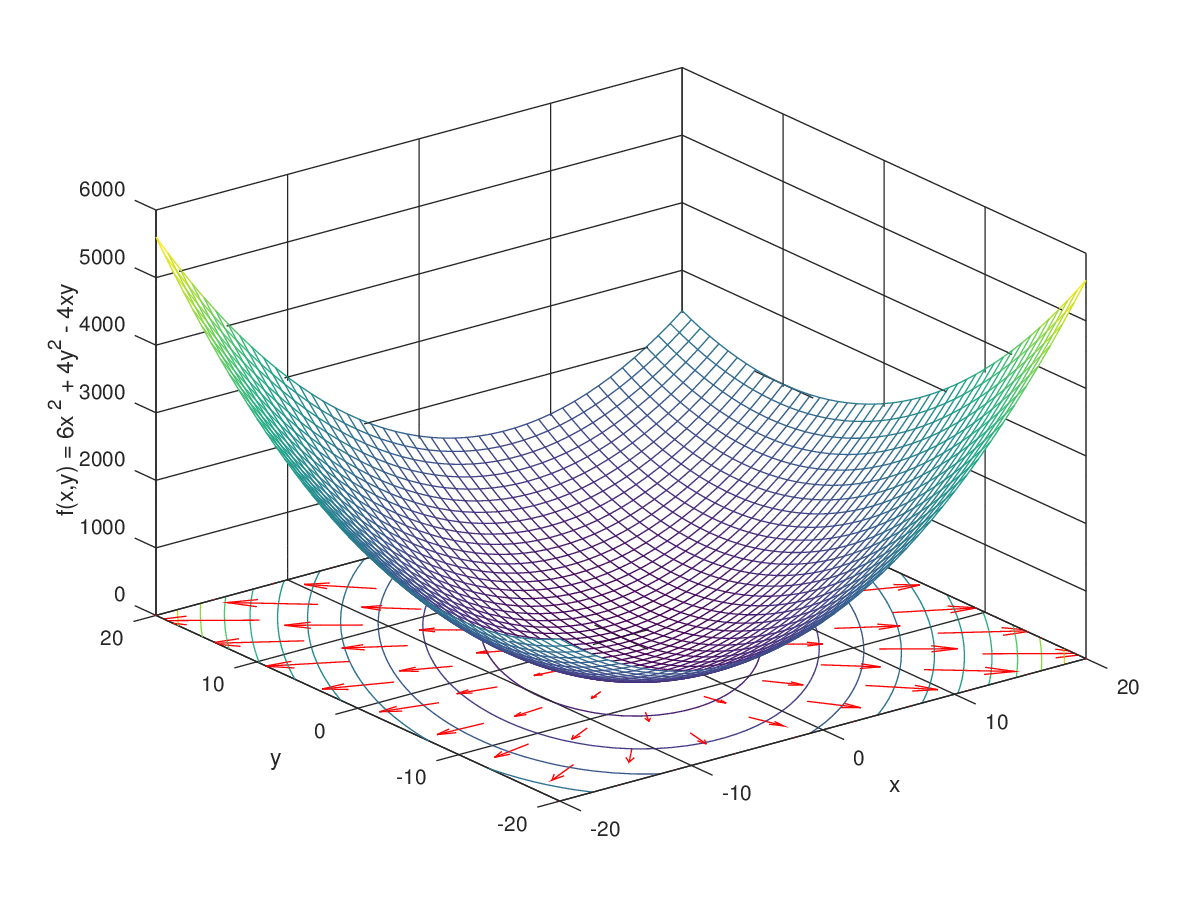
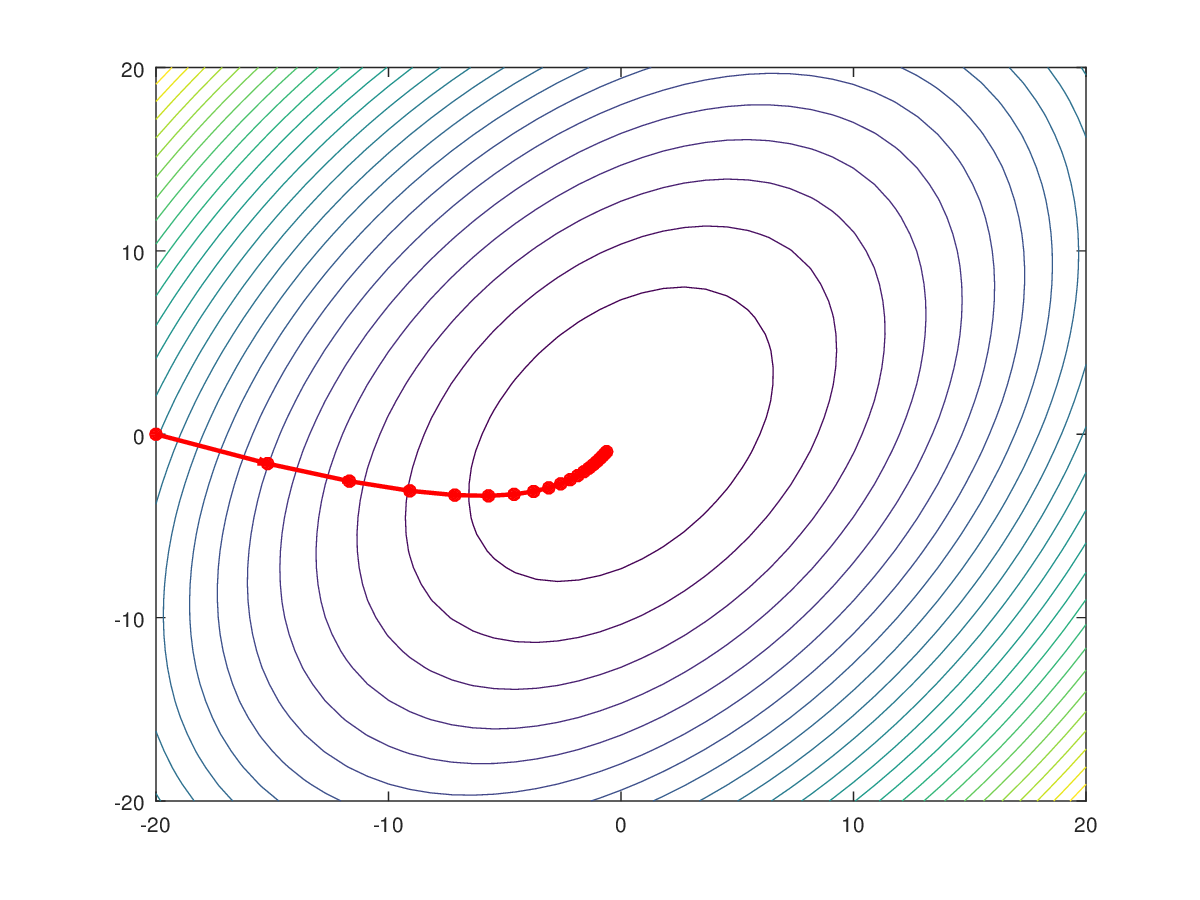
In the figures above:
- The surface represents the loss function.
- The red path shows the steps taken by gradient descent.
- Eventually the algorithm reaches the minimum.
This idea powers training in everything from:
- linear regression
- neural networks
- deep learning models
Part 1 — Understanding Derivatives Numerically¶
Before working with gradients, we need to understand derivatives.
The derivative measures how fast a function changes.
Mathematically:
This definition means:
The derivative is the slope of the tangent line.
But computers cannot evaluate limits.
Instead we approximate derivatives using finite differences. ([m3lab.github.io][1])
Forward, Backward, and Central Difference¶

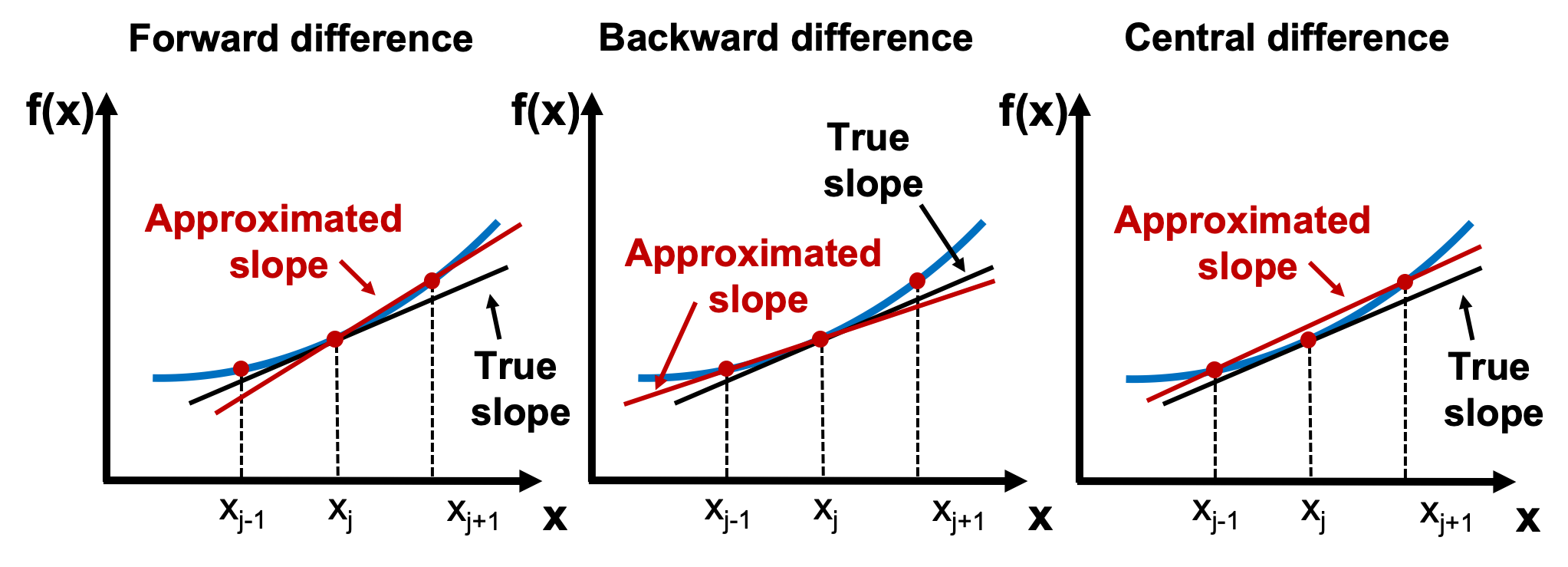

Finite difference methods approximate derivatives using nearby points.
Forward Difference¶
Python implementation:
Interpretation:
We estimate the slope by looking slightly ahead of x.
Backward Difference¶
Implementation:
Here we estimate the slope using the point just behind x.
Central Difference (Best Approximation)¶
Implementation:
This method is usually more accurate because it considers both sides of the point. ([uclnatsci.github.io][2])
Testing the Methods¶
I tested these numerical derivatives on known functions.
Example:
Derivative:
At (x = 3):
When we compute the numerical derivative, we get values extremely close to 6.
Symbolic Derivatives¶
To verify correctness, I also used SymPy.
This library computes exact derivatives symbolically.
Example:
from sympy import Symbol, sympify, diff
def symbolic_derivative(expr, var="x"):
x = Symbol(var)
sym_expr = sympify(expr)
return diff(sym_expr, x)
Example result:
returns
Part 2 — Gradients of Multivariable Functions¶
Machine learning models usually depend on many variables.
Example function:
The gradient is defined as:
Which equals:
Gradient Visualization¶

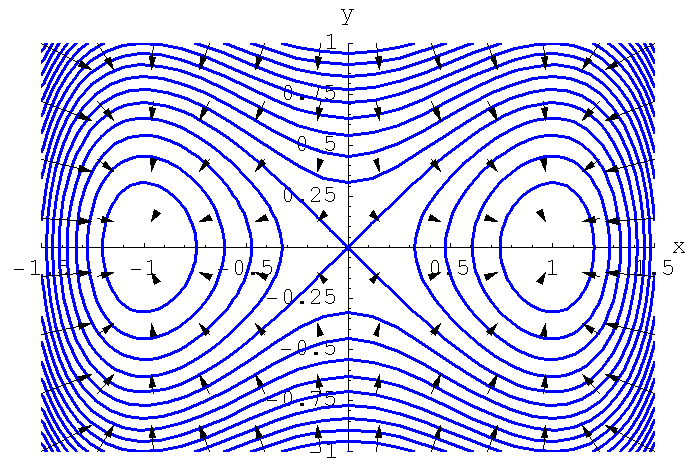

Each arrow represents the direction of steepest increase.
Key idea:
The gradient always points uphill.
To minimize loss, we move in the opposite direction.
Implementing Numerical Gradient¶
To compute gradients numerically, we slightly perturb each parameter.
Implementation:
def numerical_gradient(f, params, h=1e-6):
grad = [0.0] * len(params)
for i in range(len(params)):
original = params[i]
params[i] = original + h
f_plus = f(params)
params[i] = original - h
f_minus = f(params)
grad[i] = (f_plus - f_minus) / (2 * h)
params[i] = original
return grad
This works for any function, regardless of complexity.
Part 3 — Gradient Checking¶
When implementing machine learning algorithms manually, it is very easy to make mistakes.
Gradient checking helps verify correctness.
Steps:
- Compute analytical gradient
- Compute numerical gradient
- Compare them
Relative Error Formula¶
To compare gradients we compute:
If the error is small (e.g. (10^{-6})), the gradients match.
Implementation:
Part 4 — Linear Regression Gradient¶
Linear regression model:
Loss function: Mean Squared Error
Analytical Gradients¶
Weight gradient:
Bias gradient:
I implemented this directly in Python.
Gradient checking confirms that the analytical and numerical gradients match.
Part 5 — Neural Network Gradient¶
Finally, I applied gradient checking to a tiny neural network.
Architecture:
Sigmoid Function¶
It converts any real number into a value between 0 and 1.
This makes it useful for binary classification.
Binary Cross Entropy Loss¶
Where:
- \(y\) = true label
- \(a\) = predicted probability
Key Derivative Result¶
For sigmoid + BCE, the derivative simplifies to:
This simplification is what makes neural network training efficient.
Neural Network Gradient¶
Using the chain rule:
I implemented these gradients and verified them using gradient checking.
Why Gradient Checking Is Important¶
Even large organizations like:
- OpenAI
- Google DeepMind
- Meta AI
use gradient checking when developing new architectures.
Why?
Because even a small derivative mistake can completely break training.
What I Learned From This Project¶
Implementing everything manually helped me understand:
• Why gradients work • How optimization works mathematically • Why numerical gradients are useful for debugging • How neural network training really works
Instead of treating machine learning frameworks as black boxes, I now understand what is happening under the hood.
Final Thoughts¶
This project connected several fundamental concepts:
- Calculus
- Optimization
- Machine learning
Understanding these from first principles made the entire ML training process much clearer.
If you're learning machine learning, I strongly recommend implementing these ideas from scratch at least once.
It completely changes how you think about training models.